El siguiente artículo se compone de varias secciones:
Introducción:
La motivación inicial por la que investigar el polling fué un mensaje detectado en los logs de mi servidor:
freebsd nfe0: watchdog timeout (missed Tx interrupts) -- recovering
Como podemos ver el driver
nfe
está informando sobre pérdidas de interrupciones de recepción. El paso mas lógico fué revisar si este dispositivo estaba compartiendo IRQ con algún dispositivo de I/O que estuviese muy concurrido, pero no era el caso, la interfaz de red tenía una IRQ solo para ella.
interrupt total rate
irq1: atkbd0 2 0
irq9: acpi0 840 2
irq17: hdac0 58 0
irq18: nfe0 1 0
irq20: ohci0 440 1
irq21: ehci0 3076 7
irq22: ath0 ohci1 2 0
irq23: ehci1 18 0
cpu0:timer 546025 1164
cpu1:timer 116458 248
irq24: ahci0:ch0 31937 68
irq25: ahci0:ch1 341 1
Total 699198 1490
Así que decidí indagar un poco mas sobre el funcionamiento y gestión de dispositivos bajo FreeBSD, lo primero que debemos de tener en cuenta es que en la arquitectura Von Neumann los dispositivos de I/O necesitan mover datos del propio dispositivo a la memoria principal, cada uno de estos movimientos es gestionado por la CPU de un modo u otro existendo varias formas de realizar dicha operación:
- Polling : La CPU consulta el estado del dispositivo, si hay alguna operación pendiente procede con su ejecución, si se trata de dispositivos con poca actividad este modo de proceder es muy ineficaz ya que estaremos desperdiciando ciclos de reloj consultando dispositivos que no tienen ninguna tarea pendiente, además con polling la probabilidad de pérdida de datos es mayor ya que los dispositivos I/O tienen un buffer limitado, si no se les atiende antes de llenar el buffer, descartarán dichos datos.
- Interrupciones: El dispositivo genera una interrupción que hará que la CPU deje lo que esté haciendo y atienda al dispositivo, esto es mucho mas óptimo que el polling, el problema es que si se trata de un sistema con mucha carga la CPU será constántemente interrumpida, provocando tantos cambios de contexto que pasará mas tiempo cargando y descargando datos de los registros de la CPU que procesando información útil, dicha degradación del sistema afecta tanto a los procesos userland como a los del kernel.
- DMA: Con Direct Memory Access los dispositivos pueden acceder directamente a la memoria sin depender de la CPU, tan solo deben ser autorizados por la CPU al principio de la operación, lo que los hace mucho mas rápidos y eficientes ya que la CPU puede seguir realizando sus tareas sin interrupciones, el inconveniente es que no todo el hardware soporta este modo de funcionamiento.
Un sistema basado en interrupcions es mas impredecible que uno con polling, mediante interrupciones los eventos se generan cuando los dispositivos lo determinan, mientras que mediante polling los dispositivos se atienden de forma controlada cuando el sistema operativo lo determina y en el momento mas indicado para evitar cambios de contexto de CPU.
Mediante polling ganaremos en capacidad de respuesta del sistema, es decir cuando haya mucho I/O permanecerá mas interactivo, pero aumentará la latencia en el procesamiento de eventos, esta latencia no supone un problema en la mayoría de casos ya que en sistemas con poca carga los dispositivos son atendidos sin problemas y en sistemas con carga la latencia adicional del polling es despreciable respecto a la latencia introducida por el resto del sistema. Dicha latencia puede ser reducida de forma razonable subiendo el “clock interrupt frequency” del SO.
El polling puede resultar interesante en sistemas con mucho I/O y de poca duración como lo es el tráfico de red en servidores muy concurridos, en estos equipos el cambio de contexto de la CPU es constante desperdiciando muchos recursos útiles.
Debemos tener en cuenta que el principal objetivo del polling no es el aumento de rendimiento si no el aumento de la capacidad de respuesta, y evitar los “livelocks”, es decir la incapacidad de hacer un trabajo útil debido a pasar demasiado tiempo procesando paquetes que finalmente descartará, esto resulta útil en varios escenarios:
- Servidores que reciben ataques DoS.
- Sistemas de procesamiento pseudo real que están conectados a la red.
En cuanto a rendimiento de red el sistema presentará un comportamiento u otro según su configuración:
- Interrupciones: Optimización de los recursos del sistema mientras haya poco I/O, a partir de cierta carga el sistema corre el riesgo de quedar colgado y no responder siendo preciso un reincio completo del sistema.
- Polling: Rendimiento muy alto de forma estable independientemente del tráfico recibido pero con posibilidad de descarte de tráfico una vez superado cierto umbral.
Configuración polling:
El primer paso es comprobar que no tenemos el polling activado y aunque intentemos activarlo no seremos capaces ya que el kernel GENERIC no trae esta opción habilitada:
nfe0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8210b<RXCSUM,TXCSUM,VLAN_MTU,TSO4,WOL_MAGIC,LINKSTATE>
ether 00:22:19:eb:c7:e9
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
Podemos ver como en la línea “options” no aparece POLLING:
options=8210b<RXCSUM,TXCSUM,VLAN_MTU,TSO4,WOL_MAGIC,LINKSTATE>
Intentamos habilitarlo, pero continúa igual:
ifconfig nfe0
nfe0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8210b<RXCSUM,TXCSUM,VLAN_MTU,TSO4,WOL_MAGIC,LINKSTATE>
ether 00:22:19:eb:c7:e9
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
Además los parámetros del kernel no estarán disponibles:
sysctl: unknown oid 'kern.polling'
Para habilitar el polling tendremos que recompilar el kernel, tan solo añadiremos dicha opción el resto será una copia idéntica del kernel GENERIC.
Generamos el fichero de configuración personalizado:
mkdir /root/kernel_configs
touch /root/kernel_configs/KR0M
ln -s /root/kernel_configs/KR0M
Incluimos la configuración GENERIC y añadimos la opción DEVICE_POLLING:
include GENERIC
ident KR0M
options DEVICE_POLLING
Compilamos el kernel:
make -j2 buildkernel KERNCONF=KR0M INSTKERNNAME=kernel.kr0m
Copiamos la imagen del kernel nuevo y sus módulos a /boot/kernel.kr0m:
Retocamos nuestro loader para que cargue la imagen correcta:
kernel=kernel.kr0m
Reiniciamos para probar el kernel nuevo:
Comprobamos que imagen tenemos cargada:
FreeBSD MightyMax.alfaexploit.com 13.0-RELEASE-p11 FreeBSD 13.0-RELEASE-p11 #0 releng/13.0-n244791-312522780e8-dirty: Thu Apr 7 21:23:31 CEST 2022 root@MightyMax.alfaexploit.com:/usr/obj/usr/src/amd64.amd64/sys/KR0M amd64
Con el nuevo kernel ya podremos habilitar el polling:
nfe0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8210b<RXCSUM,TXCSUM,VLAN_MTU,TSO4,WOL_MAGIC,LINKSTATE>
ether 00:22:19:eb:c7:e9
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
ifconfig nfe0
nfe0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8214b<RXCSUM,TXCSUM,VLAN_MTU,POLLING,TSO4,WOL_MAGIC,LINKSTATE>
ether 00:22:19:eb:c7:e9
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
Podemos ver que ahora aparece POLLING en la sección options:
options=8214b<RXCSUM,TXCSUM,VLAN_MTU,POLLING,TSO4,WOL_MAGIC,LINKSTATE>
Para que el polling persista entre reinicios debemos modificar la configuración de la interfaz de red:
ifconfig_nfe0="inet 192.168.69.2 netmask 255.255.255.0 polling up"
defaultrouter="192.168.69.200"
NOTA: Si utilizamos un bridge debemos tener en cuenta que el polling se debe activar igualmente en la interfaz física, no en el bridge.
Con el kernel nuevo tendremos a nuestra disposición ciertos
parámetros de configuración
:
kern.polling.idlepoll_sleeping: 1
kern.polling.stalled: 0
kern.polling.suspect: 0
kern.polling.phase: 0
kern.polling.handlers: 0
kern.polling.residual_burst: 0
kern.polling.pending_polls: 0
kern.polling.lost_polls: 0
kern.polling.short_ticks: 0
kern.polling.reg_frac: 20
kern.polling.user_frac: 50
kern.polling.idle_poll: 0
kern.polling.each_burst: 5
kern.polling.burst_max: 150
kern.polling.burst: 5
En los tests presentados se han dejado todos los parámetros con sus valores por defecto, tuneándolos podríamos llegar a ajustar mejor nuestro sistema para llegar al punto en el que no se pierda tráfico pero que tampoco se cuelgue el sistema.
Benchmark Iperf
Instalamos el software de benchmark de red:
Ponemos a la escucha la parte del servidor:
Se realizará los tests con una duración de 1h de este modo los resultados son mas representativos que un solo test aislado, además le indicamos que muestre las estadísticas cada 1s de este modo tendremos datos en el logs cada 1s:
iperf3 -c 192.168.69.2 -t 3600 -i 1 -V --logfile POLLING.txt
Para mostrar los datos de ancho de banda y retransmisiones podemos utilizar el siguiente script:
#!/usr/bin/env bash
VALUES=$(cat $1 | grep 'Mbits/sec' | awk '{print$7" "$9}' | grep -v receiver)
rm /tmp/bandwith
rm /tmp/retransmissions
IFS=$'\n'
COUNTER=0
for VALUE in $VALUES; do
BW_VALUE=$(echo $VALUE|awk '{print$1}')
#echo "BW_VALUE: $BW_VALUE"
echo "$COUNTER $BW_VALUE" >> /tmp/bandwith
RETRANS_VALUE=$(echo $VALUE|awk '{print$2}')
#echo "RETRANS_VALUE: $RETRANS_VALUE"
echo "$COUNTER $RETRANS_VALUE" >> /tmp/retransmissions
let COUNTER=$COUNTER+1
done
gnuplot -p -e "plot '/tmp/bandwith' title 'Mbits/sec' with lp; replot '/tmp/retransmissions' title 'Retransmissions' with lp"
Le asignamos los permisos necesarios y lo ejecutamos, el script tardará un rato ya que son muchos datos y bash no es precisamente rápido:
./iperfGraph.sh GENERIC.txt
./iperfGraph.sh POLLING.txt
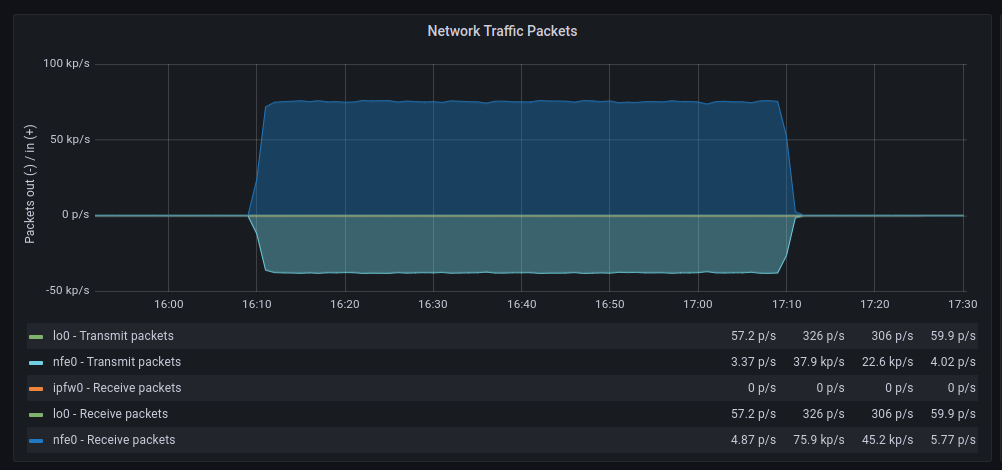
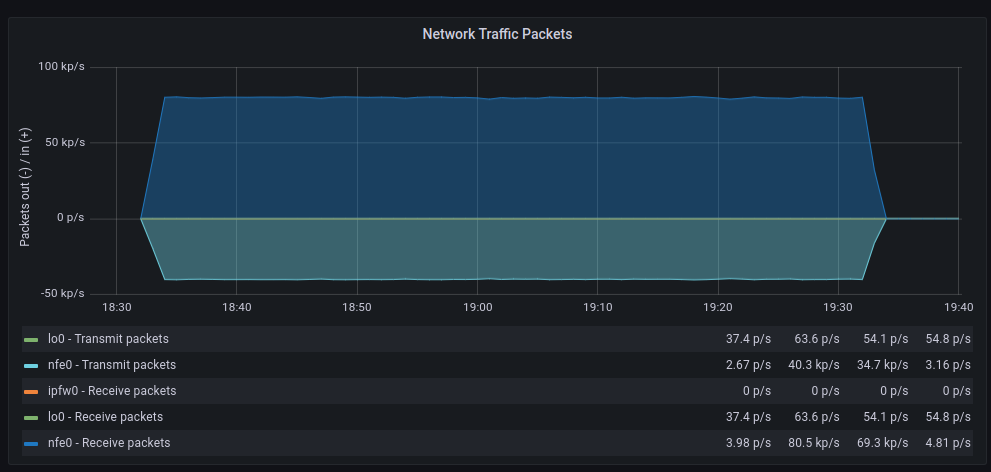
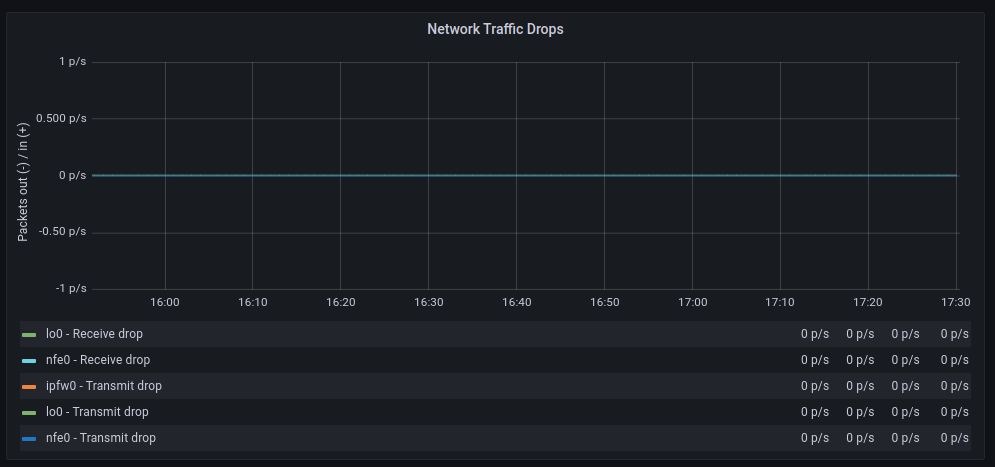
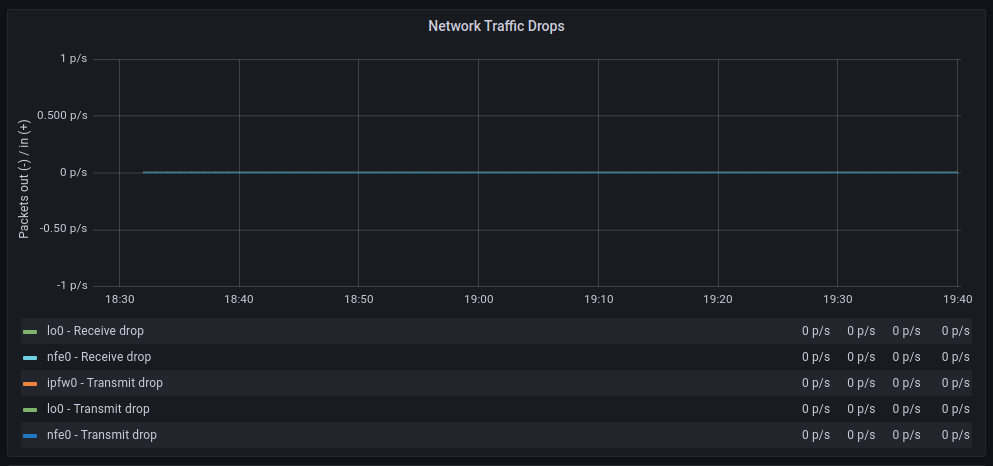
Para dar una visión mas amplia también consultaremos las métricas de nuestro Prometheus:
| GENERIC | POLLING |
|---|---|
|
|
|
|
|
|
|
|
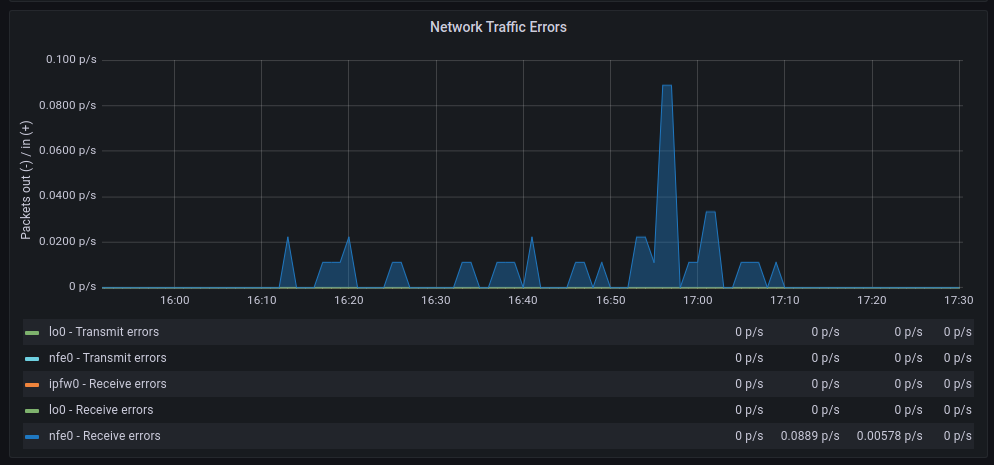
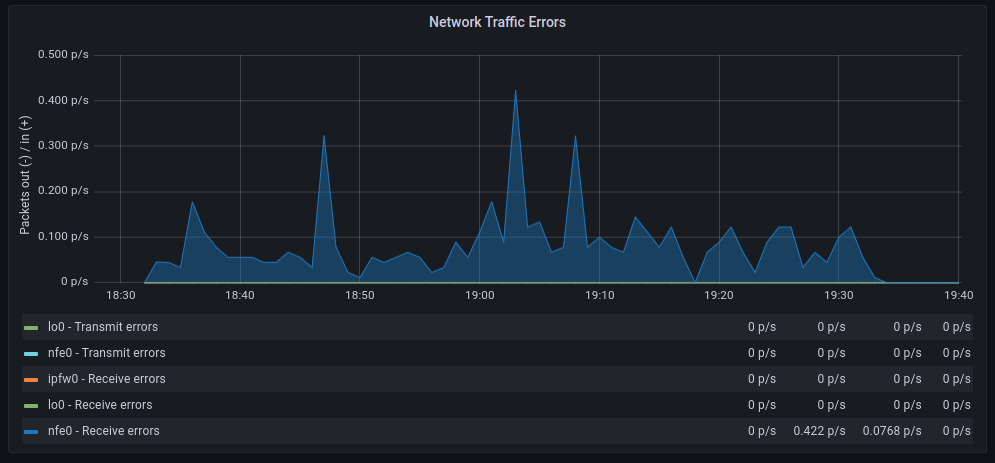
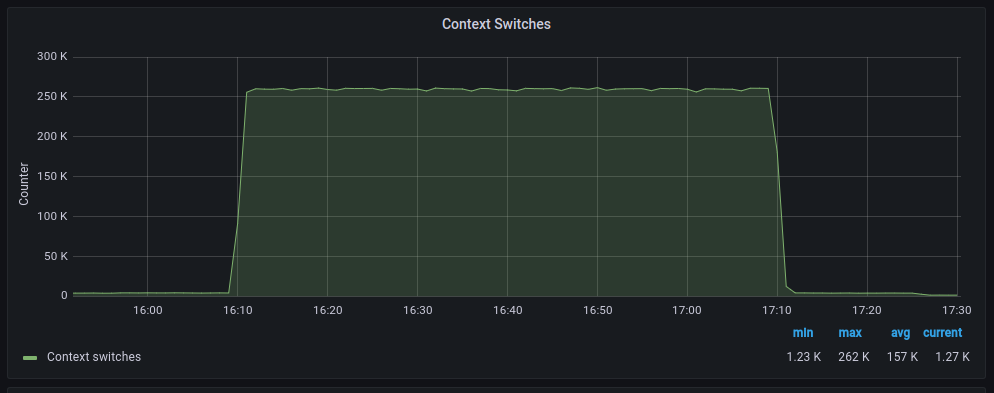
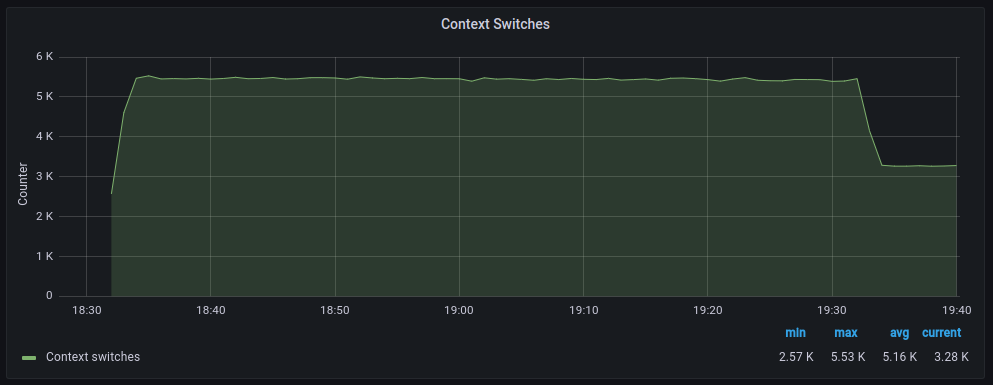
Las tasas de transferencia media son muy similares aunque con polling parece que hay mas retransmisiones, en cuanto a paquetes descartados el comportamiento es muy similar, en cambio los errores aumentan significativamente cuando hacemos polling, por otra parte los cambios de contexto disminuyen drásticamente tal y como cabía esperar.
Conclusión
El polling funciona bien cuando se aplica en sistemas con muchísima carga pero se deben ajustar los parámetros de polling para llegar al punto en el que no se descarte tráfico pero sin llegar a colgar el sistema.
Se trata de buscar el balance perfecto de tiempo de polling de dispositivos y el tiempo empleado en atender kernel+userland, cada sistema tiene unos drivers específicos de red, una carga determinada y unos requisitos específicos por lo tanto la única manera de hayar dicho punto es ir experimentando.
Una vez tuneado el sistema quizás sería interesante configurar alertas cuando se supere cierto umbral de descarte de tráfico en el servidor, este sería un buen indicativo de que debemos añadir mas nodos al cluster de servidores.
Mi recomendación rápida es:
- Interrupciones: Servidores con un volúmen de tráfico bajo/medio, las interrupciones no supondrán un problema y se dispondrá del 100% de cpu-power para procesos locales.
- Polling: Servidores con mucho tráfico donde experimentemos cuelgues utilizando interrupciones, ganaremos en estabilidad pero no dispondremos del 100% de cpu-power para procesos locales ya que el polling consumirá parte de él.