En este artículo se describen una serie de recomendaciones a tener en cuenta a la hora de poner en producción un servidor Mongo bajo Linux, se cubren aspectos como el kernel, sistema de ficheros, consideraciones a tener en cuenta con SELinux/GrSec entre otros.
Estas son solo unas consideraciones básicas, por supuesto cada escenario está vinculado a sus propias particularidades.
Kernel
2.6.36 o posterior.
Sistema de ficheros
XFS o Ext4, preferiblemente XFS, Mongo requiere un sistema de ficheros que soporte la llamada fsync() sobre directorios. Algunos sistemas de ficheros exóticos como HGFS o carpetas compartidas de VBox no lo soportan.
Meter la opción atime en la partición donde estén los ficheros de la DB.
El readahead es beneficioso cuando se realizan lecturas sobre zonas continuas del disco, pero mongo no sigue dicho patrón si no que realiza lecturas aleatorias.
blockdev --setra 32 /dev/sda
blockdev --getra /dev/sda
32
Podemos hacerlo en el arranque del SO:
#! /bin/bash
blockdev --setra 32 /dev/sda
Límites del SO
Los parámetros recomendados por mongo son:
-f (file size): unlimited
-t (cpu time): unlimited
-v (virtual memory): unlimited
-n (open files): 64000
-m (memory size): unlimited
-u (processes/threads): 64000
mongodb soft fsize unlimited
mongodb hard fsize unlimited
mongodb soft cpu unlimited
mongodb hard cpu unlimited
mongodb soft as unlimited
mongodb hard as unlimited
mongodb soft nofile 64000
mongodb hard nofile 64000
mongodb soft nproc 64000
mongodb hard nproc 64000
Con este pequeño script podemos comprobar si todo está en regla:
#! /bin/bash
for process in $@; do
process_pids=`ps -C $process -o pid --no-headers | cut -d " " -f 2`
if [ -z $@ ]; then
echo "[no $process running]"
else
for pid in $process_pids; do
echo "[$process #$pid -- limits]"
cat /proc/$pid/limits
done
fi
done
NTP
Especialmente importante para los clusters con sharding.
Transparent Huge Pages
La correspondencia entre memoria virtual y física es llevada a cabo por la MMU de la CPU, este proceso es relativamente lento, para mitigar dicha lentitud se creó una caché de mapeos llamada TLB pero la TLB es de tamaño limitado por lo que las entradas están continuamente cambiando.
Como la TLB es limitada lo que se puede hacer es hacer las páginas de memoria mas grandes de este modo cubrimos mas espacio de memoria física con las mismas entradas en la TLB.
- Huge pages es apropiado para aplicaciones que accedan a grandes regiones de memoria continua
- No funciona con aplicaciones que acceden a pequeñas porciones de memoria en distintas posiciones, como es el caso de mongo
Añadimos el deshabilitar las hugepages en el script de arranque:
#! /bin/bash
blockdev --setra 32 /dev/sda
if [ -d /sys/kernel/mm/transparent_hugepage ]; then
thp_path=/sys/kernel/mm/transparent_hugepage
elif [ -d /sys/kernel/mm/redhat_transparent_hugepage ]; then
thp_path=/sys/kernel/mm/redhat_transparent_hugepage
else
return 0
fi
echo 'never' > ${thp_path}/enabled
echo 'never' > ${thp_path}/defrag
re='^[0-1]+$'
if [[ $(cat ${thp_path}/khugepaged/defrag) =~ $re ]]; then
# RHEL 7
echo 0 > ${thp_path}/khugepaged/defrag
else
# RHEL 6
echo 'no' > ${thp_path}/khugepaged/defrag
fi
unset re
unset thp_path
NUMA
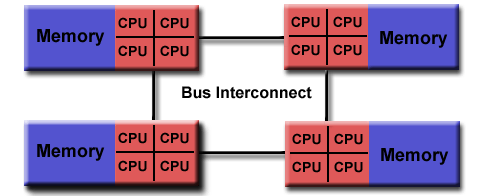
La arquitectura NUMA fué diseñada para superar los problemas de escalabilidad en arquitecturas SMP, en esta todas las CPUs compiten por el acceso al bus de la memoria RAM provocando de este modo un cuello de botella. NUMA por otra parte propone un bus de acceso a RAM por cada X CPUs, siendo el acceso a esta RAM mas rápido que el acceso a una RAM de otro grupo de CPUs.
Sobre el papel NUMA pinta muy bien pero se sabe que Mongo no funciona correctamente en este tipo de entornos, primero averiguamos si nuestro hardware soporta NUMA:
numactl –hardware
available: 1 nodes (0) --> Solo hay un nodo, NO es NUMA: Intel Xeon CPU E5-1660 v3 @ 3.00GHz
available: 2 nodes (0-1) --> Sí es NUMA: AMD Opteron Processor 4386
Para deshabilitarlo:
sysctl -w vm.zone_reclaim_mode=0
Arrancamos mongo mediante numactl:
cd
screen -S mongo
numactl –interleave=all /usr/bin/mongod –config /etc/mongodb.conf
SELinux
Es problemático:
https://docs.mongodb.com/manual/tutorial/install-mongodb-on-red-hat/#install-rhel-configure-selinux
GrSec
https://jira.mongodb.org/browse/SERVER-12991
V8, the Javascript engine used by mongodb, requires the ability to write executable pages of memory for Just-In-Time (JIT) compilation.
If an operating system has been configured so it’s not possible to write to executable memory regions, V8 cannot function.