Linux nos permite una gran flexibilidad en cuanto a sistemas de ficheros, configuración de raids y volúmenes lógicos mediante LVM, este artículo es una breve introducción a RAID para poder en artículos posteriores configurar de forma correcta el tipo de raid que mas nos interese.
Lo primero que debemos hacer es compilar el kernel con soporte para RAID:
Device Drivers --> Multiple devices driver support (RAID and LVM)
En esta sección elegimos los tipos de raid que necesitemos y las opciones que nos resulten útiles, para probar lo mejor es habilitarlo todo excepto las opciones en fase experimental a no ser que nos guste jugar con fuego ya que si el raid falla el SO ya no arrancará :(
A continuación detallo de forma breve las principales características de los tipos de raid soportados en Linux:
Linear Mode
Nos presenta una partición detrás de otra como si se tratase de una partición mas grande.
RAID0
Se escribe de forma simultanea en todos los discos, la info queda repartida entre todos los discos, si uno falla todo se va al garete.
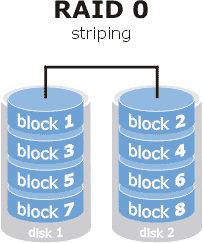
- Tolerancia de fallo: 0
- Acceso de lectura aleatorio: Muy bueno.
- Acceso de escritura aleatorio: Muy bueno.
- Acceso de lectura secuencial: Muy bueno- Excelente.
- Acceso de escritura secuencial: Muy bueno.
RAID1
Este tipo de raid nos proporciona mirroring, cada disco tiene una copia exacta de los datos en otro disco, las escrituras se ve penalizadas ya que tiene que escribir en los dos discos pero las lecturas se ven favorecidas al poder leer en paralelo.
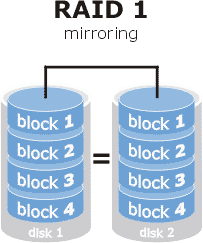
- Tolerancia de fallo: 1
- Acceso de lectura aleatorio: Bueno, lectura en paralelo de los diferentes discos.
- Acceso de escritura aleatorio: Bueno, peor que un solo disco.
- Acceso de lectura secuencial: Medio, mas o menos como un disco único.
- Acceso de escritura secuencial: Bueno.
RAID2
La info se reparte a nivel de bit entre un grupo de discos, en otros se reparte la información de ECC con la que somos capaces de reparar la errores de un bit.
Cuando se escribe se calcula el ECC y cuando se lee se comprueba. Solo puede recuperarse si falla un disco, no se tiene acceso simultáneo a los datos.
Las configuraciones suelen ser:
- 10 data disks and 4 ECC disks
- 32 data disks and 7 ECC disks
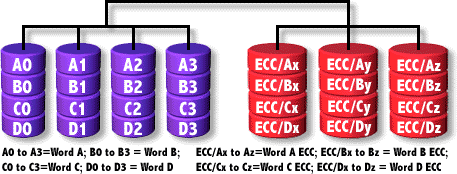
- Tolerancia de fallo: 1
- Acceso de lectura aleatorio: Medio, acceso multiple imposible.
- Acceso de escritura aleatorio: Pobre, debido al reparto a nivel de bit y al calculo del ECC.
- Acceso de lectura secuencial: Muy bueno, debido al paralelismo de varios dispositivos.
- Acceso de escritura secuencial: Medio-Bueno.
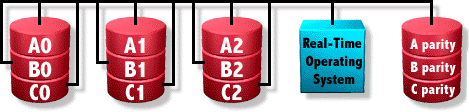
RAID3
Se emplean N discos para datos y uno de ellos para paridad, los datos se escriben a nivel de BYTE entre los discos de datos de forma paralela.
El disco de paridad puede suponer un cuello de botella. Puede fallar un disco sin problemas, incluyendo el de paridad, este tipo de raid impone un mínimo de tres discos.
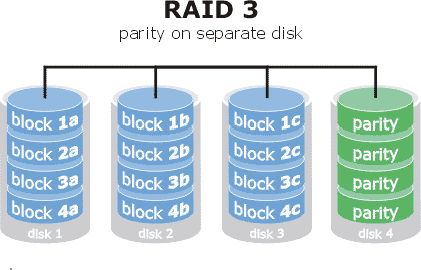
- Tolerancia de fallo: 1
- Acceso de lectura aleatorio: Bueno
- Acceso de escritura aleatorio: Pobre por el el reparto a nivel de byte, calculo de paridad y el cuello de botella del disco de paridad.
- Acceso de lectura secuencial: Muy bueno.
- Acceso de escritura secuencial: Medio-Bueno.
RAID4
Se emplean N discos para datos y uno de ellos para paridad, los datos se escriben a nivel de BLOQUE entre los discos de datos de forma paralela.
El disco de paridad puede suponer un cuello de botella.
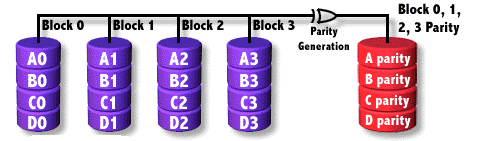
- Tolerancia de fallo: 1
- Acceso de lectura aleatorio: Muy bueno
- Acceso de escritura aleatorio: Pobre-Bueno debido al calculo de paridad y al cuello de botella del disco de paridad.
- Acceso de lectura secuencial: Bueno-Muy bueno.
- Acceso de escritura secuencial: Medio-Bueno.
RAID5
Tanto los datos como la paridad se distribuye entre todos los discos, la información se escribe a nivel de bloque.
El tamaño del bloque se puede ajustar para conseguir mayor rendimiento.
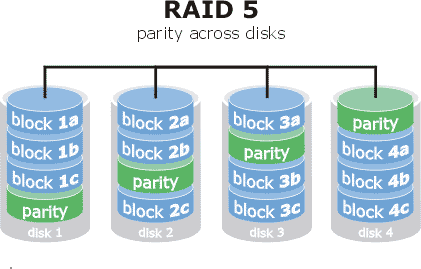
- Tolerancia de fallo: 1
- Acceso de lectura aleatorio: Muy bueno-Excelente, suele mejorar cuando el tamaño de bloque es grande, en las lecturas no se realiza la comprobación de paridad.
- Acceso de escritura aleatorio: Medio debido a que hay que escribir la paridad.
- Acceso de lectura secuencial: Bueno-Muy bueno, suele mejorar cuando el tamaño de bloque es pequeño.
- Acceso de escritura secuencial: Medio-Bueno
RAID6
Exactamente igual que RAID5 pero la paridad se escribe por duplicado.
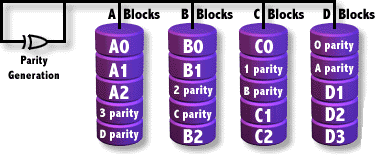
- Tolerancia de fallo: 2
- Acceso de lectura aleatorio: Muy bueno-Excelente, suele mejorar cuando el tamaño de bloque es grande
- Acceso de escritura aleatorio: Calculo de paridad doble
- Acceso de lectura secuencial: Bueno-Muy bueno, suele mejorar cuando el tamaño de bloque es pequeño.
- Acceso de escritura secuencial: Medio
RAID7
No existe, es simplemente un término de marketing de Storage Computer Corporation.
Basado en raid3/4 con un sistema de cache por niveles y hardware de acceso a la controladora.
- Acceso de lectura aleatorio: Muy bueno-Excelente, debido a la cache
- Acceso de escritura aleatorio: Muy bueno
- Acceso de lectura secuencial: Muy bueno-Excelente
- Acceso de escritura secuencial: Muy bueno |
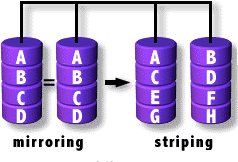
Nested
Se trata de anidar raids dentro de raids, sí matrix dentro de matrix ;)
Empleamos las unidades del primer raid para generar un segundo.
Términos importantes:
- Disco Spare: Este se queda de backup, no se utiliza hasta que es necesario reemplazar alguno que haya fallado. Se puede compartir spare entre arrays raid.
- ChunckSize: Tamaño mínimo de información que se puede escribir, si se tiene que partir un datos entre diferentes discos se parte en trocitos de este tamaño. Se indica en KB
Cuando se trata de ficheros grandes es recomendable un chunck grande para que no esté pasando continuamente de un disco al otro perdiendo el tiempo.
mdadm --create [md-device] --chunk=X --level=Y --raid-devices=Z [devices]
- Block-Size: Otro factor a tener en cuenta es el block-size del sistema de ficheros, este es la unidad mínima de escritura en un sistema de ficheros. Si tenemos ficheros pequeños nos interesa un valor bajo, si solemos tratar con ficheros grandes nos interesa grande, de forma gráfica se puede ver muy fácilmente:
Supongamos que tenemos un tamaño de bloque de 2KB y queremos escribir un fichero de 3KB, en este caso se generaría fragmentación ya que quedaría así:

Si el tamaño de bloque fuese 1KB:

Como podemos ver no habría fragmentación debido a este fichero ;)
- Ensamblar raid: Para que el SO pueda utilizar el raid este debe ser ensamblado primero, esto quiere decir montame el raid llamado /dev/mdX utilizando las unidades /dev/
vdXX /dev/vdYY ….
Podemos encontrar algunos benchmarks aquí .