Linux allows us great flexibility in terms of file systems, RAID configuration, and logical volumes through LVM. This article is a brief introduction to RAID so that we can correctly configure the type of RAID that interests us most in subsequent articles.
The first thing we need to do is compile the kernel with RAID support:
Device Drivers --> Multiple devices driver support (RAID and LVM)
In this section, we choose the types of RAID we need and the options that are useful to us. For testing, it is best to enable everything except the options in the experimental phase unless we like to play with fire since if the RAID fails, the OS will not boot :(
Next, I briefly detail the main characteristics of the types of RAID supported in Linux:
Linear Mode
It presents a partition behind another as if it were a larger partition.
RAID0
It is written simultaneously on all disks, the information is distributed among all disks, if one fails, everything goes to waste.
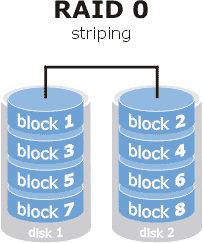
- Fault tolerance: 0
- Random read access: Very good.
- Random write access: Very good.
- Sequential read access: Very good- Excellent.
- Sequential write access: Very good.
RAID1
This type of RAID provides us with mirroring, each disk has an exact copy of the data on another disk, the writes are penalized since it has to write to both disks, but the reads are favored by being able to read in parallel.
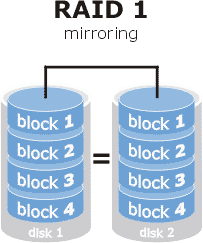
- Fault tolerance: 1
- Random read access: Good, parallel reading from different disks.
- Random write access: Good, worse than a single disk.
- Sequential read access: Medium, more or less like a single disk.
- Sequential write access: Good.
RAID2
The information is distributed at the bit level among a group of disks, in others the ECC information is distributed with which we are able to repair one-bit errors.
When writing, the ECC is calculated and when reading it is checked. It can only be recovered if one disk fails, simultaneous access to the data is not available.
The configurations are usually:
- 10 data disks and 4 ECC disks
- 32 data disks and 7 ECC disks
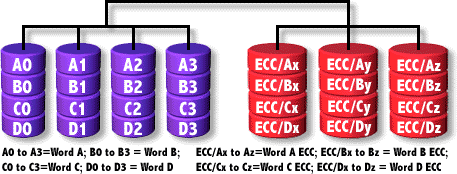
- Fault tolerance: 1
- Random read access: Medium, multiple access impossible.
- Random write access: Poor, due to bit-level distribution and ECC calculation.
- Sequential read access: Very good, due to parallelism of several devices.
- Sequential write access: Medium-Good.
RAID3
N disks are used for data and one for parity, the data is written at the BYTE level between the data disks in parallel.
The parity disk can be a bottleneck. A disk can fail without problems, including the parity disk, this type of raid imposes a minimum of three disks.
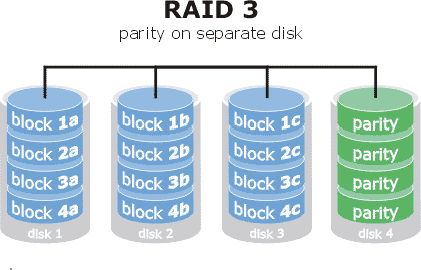
- Fault tolerance: 1
- Random read access: Good
- Random write access: Poor due to byte-level distribution, parity calculation, and the bottleneck of the parity disk.
- Sequential read access: Very good.
- Sequential write access: Medium-Good.
RAID4
N disks are used for data and one for parity, the data is written at the BLOCK level between the data disks in parallel.
The parity disk can be a bottleneck.
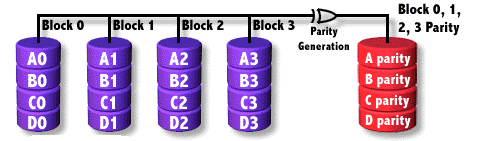
- Fault tolerance: 1
- Random read access: Very good
- Random write access: Poor-Good due to parity calculation and the bottleneck of the parity disk.
- Sequential read access: Good-Very good.
- Sequential write access: Medium-Good.
RAID5
Both data and parity are distributed among all disks, information is written at the block level.
The block size can be adjusted to achieve higher performance.
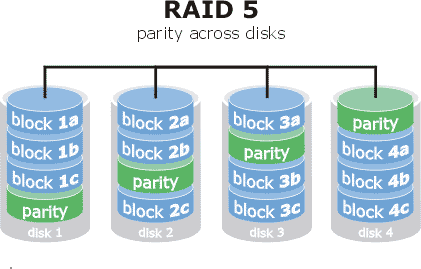
- Fault tolerance: 1
- Random read access: Very good-Excellent, usually improves when the block size is large, parity check is not performed during reads.
- Random write access: Medium because parity needs to be written.
- Sequential read access: Good-Very good, usually improves when the block size is small.
- Sequential write access: Medium-Good
RAID6
Exactly the same as RAID5 but parity is written twice.
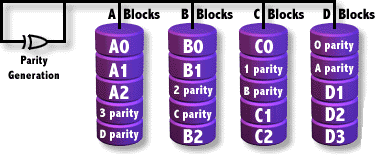
- Fault tolerance: 2
- Random read access: Very good-Excellent, usually improves when the block size is large.
- Random write access: Double parity calculation.
- Sequential read access: Good-Very good, usually improves when the block size is small.
- Sequential write access: Medium
RAID7
It does not exist, it is simply a marketing term from Storage Computer Corporation.
Based on raid3/4 with a multi-level cache system and hardware access to the controller.
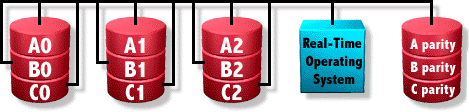
- Random read access: Very good-Excellent, due to the cache.
- Random write access: Very good.
- Sequential read access: Very good-Excellent.
- Sequential write access: Very good.
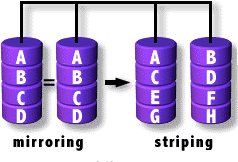
Nested
It consists of nesting raids within raids, yes matrix within matrix ;)
We use the units of the first raid to generate a second one.
Important terms:
- Spare Disk: This is kept as a backup, it is not used until it is necessary to replace a failed one. Spare can be shared between raid arrays.
- ChunkSize: Minimum size of information that can be written, if data needs to be split between different disks, it is split into pieces of this size. It is indicated in KB.
When dealing with large files, it is recommended to use a large chunk size to avoid constantly switching between disks and wasting time.
mdadm --create [md-device] --chunk=X --level=Y --raid-devices=Z [devices]
- Block-Size: Another factor to consider is the block size of the file system, which is the minimum unit of writing in a file system. If we have small files, we want a low value, if we usually deal with large files, we want a large value. This can be easily seen graphically:
Suppose we have a block size of 2KB and we want to write a 3KB file, in this case fragmentation would occur as follows:

If the block size were 1KB:

As we can see, there would be no fragmentation due to this file ;)
- Assemble RAID: In order for the OS to use the RAID, it must be assembled first. This means mounting the RAID called /dev/mdX using the units /dev/vdXX /dev/vdYY ….
You can find some benchmarks here .