RabbitMQ is a message queuing software called a message broker or queue manager. Simply put, it is a software where queues can be defined, applications can connect to those queues, and transfer/read messages in them.
Before we start, we must clarify certain peculiarities of Rabbit:
- Rabbit depends heavily on the names of the computers (Erlang), all nodes and connection tools that we are going to use must resolve the names in the same way (RABBITMQ_USE_LONGNAME).
- All information/states are replicated on all nodes except for queues (although they are accessible between nodes).
- There is another type of queue called Quorum queues, but they are not durable, they are not saved on disk .
- Clusters must have an odd number of nodes to avoid split-brain problems.
- When all nodes are available, the client can connect to each of them independently, the nodes will route operations to the node that has the queue in question transparently.
- In case of a node failure, clients must be able to reconnect to a different node, retrieve the topology, and continue to function. Most client libraries allow configuring a list of nodes.
- It may happen that the client connects to another node but the queue does not exist (this problem is solved with queue replication).
- Connections, channels, and queues are distributed among the nodes of the cluster.
- When a node is stopped, before stopping, it chooses one of the online nodes, when it starts again, it will try to resynchronize from this node, if RabbitMQ cannot do it, it will not start.
- If when a node is being shut down, there are no other nodes up, when it starts, it will not try to synchronize with anyone.
- The clustering system is designed to be used between nodes in the same network segment, if it is necessary to deploy it in WAN, plugins such as Shovel or Federation must be used.
We compile and install the server:
NOTE: I had to unmask the rabbit server because the stable version requires an Elixir version that is no longer in the portage and shows the following error when compiling:
(Mix) You’re trying to run :rabbitmqctl on Elixir v1.10.0 but it has declared in its mix.exs file it supports only Elixir >= 1.6.6 and < 1.9.0
We start the servers in standalone mode, for which we must define the UTF8 locales, otherwise the service will not start:
LANG="es_ES.utf8"
LC_COLLATE="C"
EOF
es_ES.utf8 UTF-8
es_ES@euro ISO-8859-15
EOF
env-update
reboot
To start, we must have the hosts file modified so that the server name points to the loopback:
127.0.0.1 localhost kr0mtest
#arguments for run erlang
command_args="-address 0.0.0.0"
We stop rabbit if it was running:
We make sure to kill all epm (Erlang Port Mapper Daemon) processes:
We start again, this time with the new configuration:
We check for any possible errors:
We add the service to the startup:
NOTE: All cluster nodes must share the erlang-cookie, copy from node1 (for example) to the rest of the nodes.
We check the cookie:
On the rest of the nodes, we stop the service, replace the cookie, and start again:
vi /var/lib/rabbitmq/.erlang.cookie
/etc/init.d/rabbitmq start
Let’s join nodes 2,3 to 1, for this we execute on node2/3:
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@kr0mtest
rabbitmqctl start_app
The cluster status can be checked from any node:
Cluster status of node rabbit@kr0mtest3 ...
Basics
Cluster name: rabbit@localhost
Disk Nodes
rabbit@kr0mtest
rabbit@kr0mtest2
rabbit@kr0mtest3
Running Nodes
rabbit@kr0mtest
rabbit@kr0mtest2
rabbit@kr0mtest3
Versions
rabbit@kr0mtest: RabbitMQ 3.8.2 on Erlang 22.2.1
rabbit@kr0mtest2: RabbitMQ 3.8.2 on Erlang 22.2.1
rabbit@kr0mtest3: RabbitMQ 3.8.2 on Erlang 22.2.1
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@kr0mtest, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@kr0mtest, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@kr0mtest2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@kr0mtest2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@kr0mtest3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@kr0mtest3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: implicit_default_bindings, state: enabled
Flag: quorum_queue, state: enabled
Flag: virtual_host_metadata, state: enabled
If we need to remove a node from the cluster, we stop the app on it and remove it from any other node:
kr0mtest3 ~ # rabbitmqctl forget_cluster_node rabbit@kr0mtest4
To be able to see the status of the cluster/queues more easily, we will install the management plugin, we must do it on all nodes:
We will see a new socket:
tcp 0 0 0.0.0.0:15672 0.0.0.0:* LISTEN 6833/beam.smp
We check the users:
Listing users ...
user tags
guest [administrator]
The guest user is only for local use, it cannot be logged in remotely:
This is a new features since the version 3.3.0. You can only login using guest/guest on localhost.
We create an administrator user on one of the nodes, this one will be able to access via web:
rabbitmqctl set_user_tags kr0m administrator
rabbitmqctl set_permissions -p / kr0m “.” “.” “.*”
Listing users ...
user tags
kr0m [administrator]
guest [administrator]
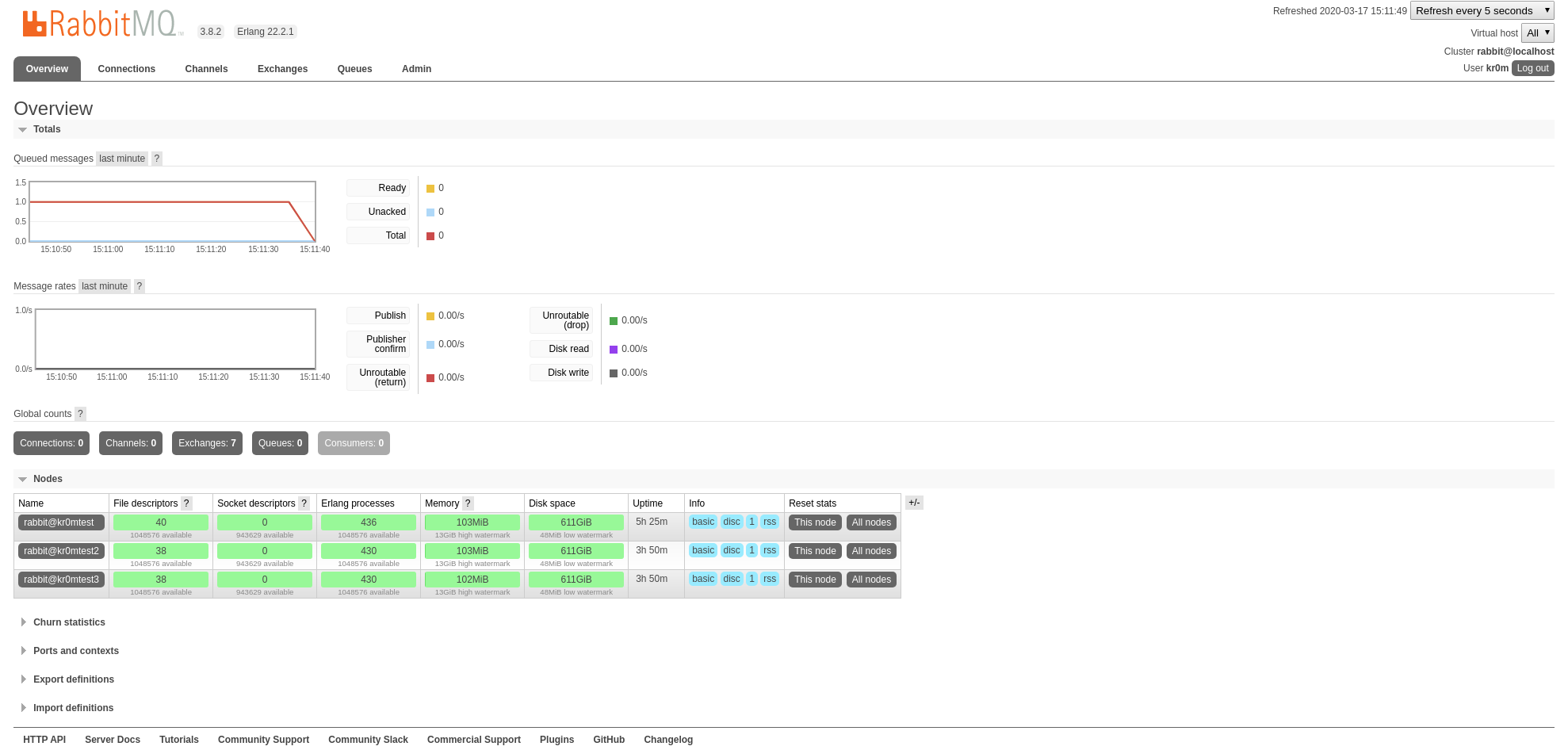
To be able to perform our tests from Python we will have to install the pika library:
Let’s create a test queue:
import pika, os, logging
logging.basicConfig()
# Parse CLODUAMQP_URL (fallback to localhost)
url = os.environ.get('CLOUDAMQP_URL', 'amqp://kr0m:s3crEt@kr0mtest/%2f')
params = pika.URLParameters(url)
params.socket_timeout = 5
connection = pika.BlockingConnection(params) # Connect to CloudAMQP
channel = connection.channel() # start a channel
channel.queue_declare(queue='kr0mQueue') # Declare a queue
# send a message
channel.basic_publish(exchange='', routing_key='kr0mQueue', body='testBody')
print ("[x] Message sent to consumer")
connection.close()
We run the script and check that the queue has been created and has a message:
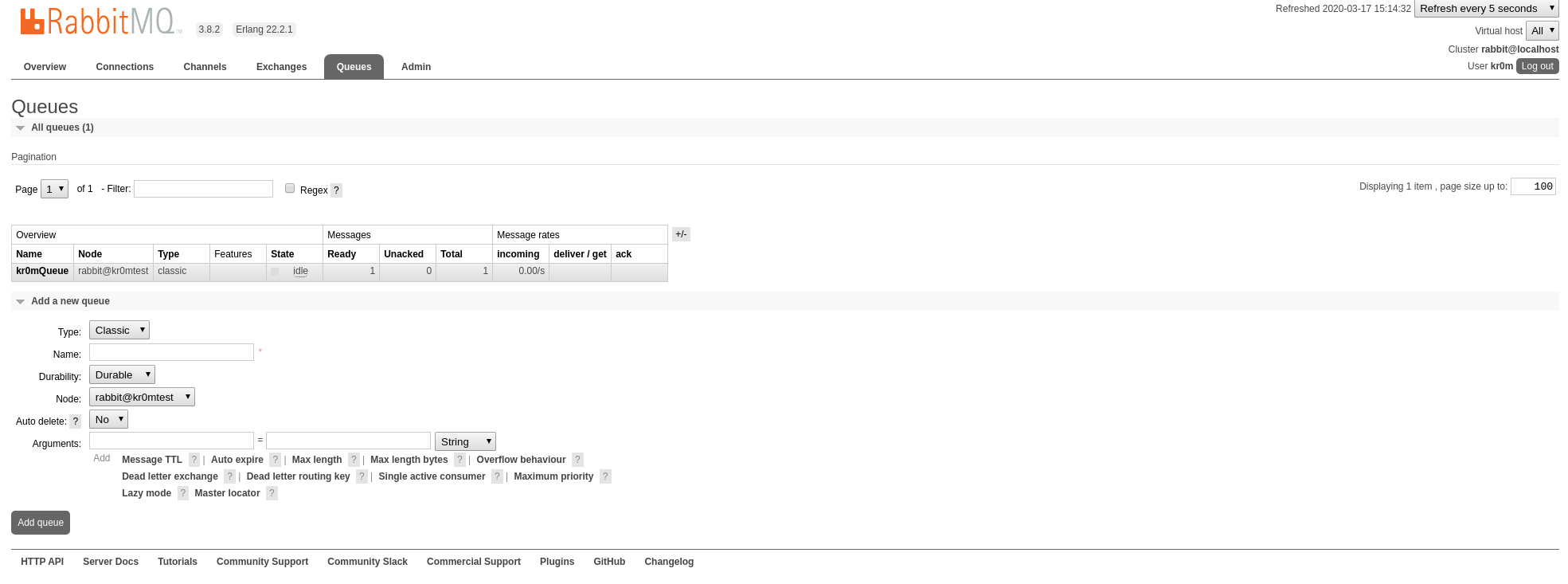
Now we program a consumer:
import pika, os
def processMessage(msg):
print(" [x] Received " + str(msg))
return;
# create a function which is called on incoming messages
def callback(ch, method, properties, body):
processMessage(body)
# Parse CLODUAMQP_URL (fallback to localhost)
url = os.environ.get('CLOUDAMQP_URL', 'amqp://kr0m:s3crEt@kr0mtest/%2f')
params = pika.URLParameters(url)
params.socket_timeout = 5
connection = pika.BlockingConnection(params) # Connect to CloudAMQP
channel = connection.channel() # start a channel
#set up subscription on the queue
channel.basic_consume('kr0mQueue', callback, auto_ack=True)
channel.start_consuming() # start consuming (blocks)
connection.close()
We can see how it gets the message from the queue:
[x] Received b'testBody'
For queue synchronization, we follow the guide .
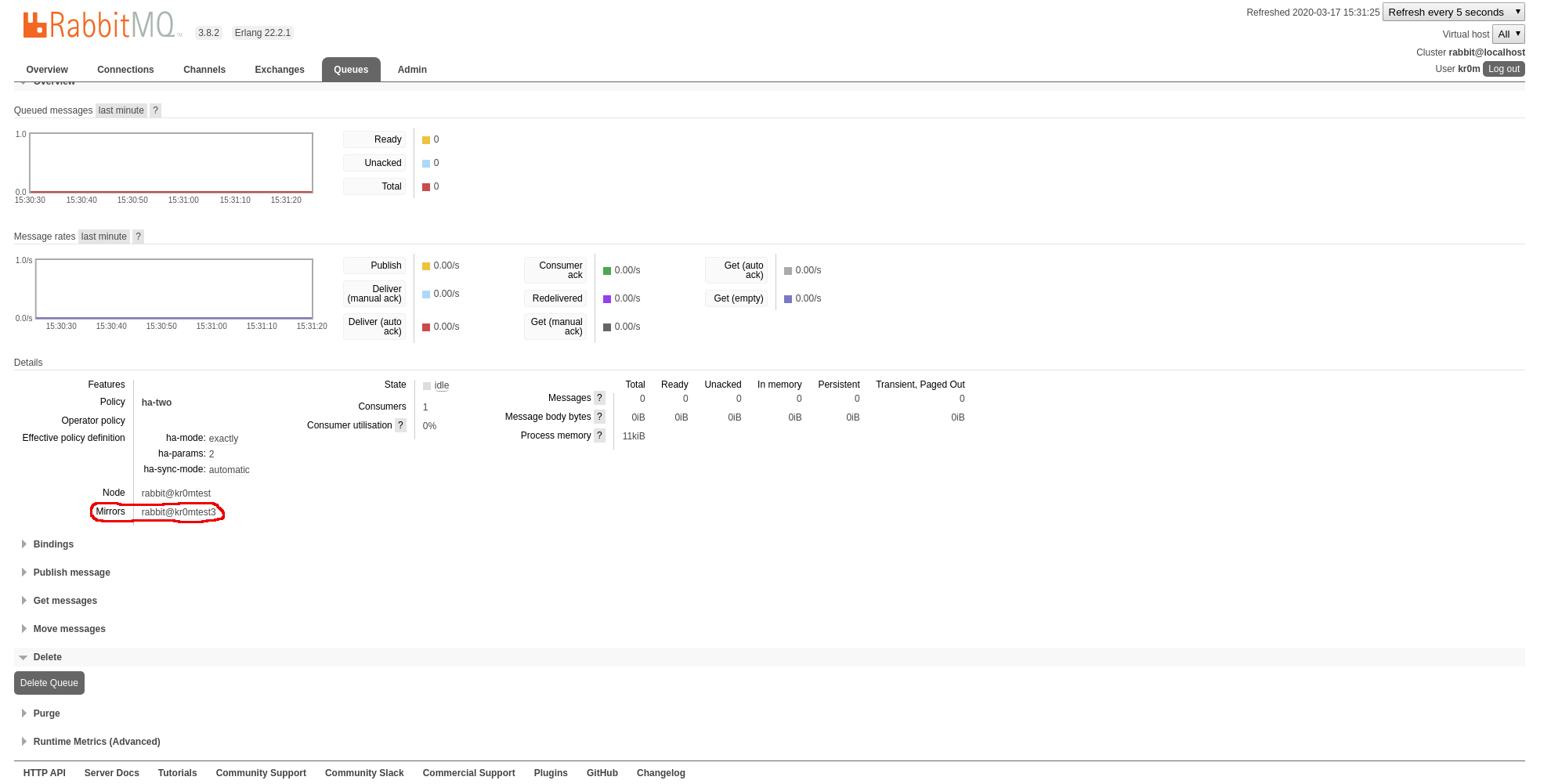
Each mirrored queue has a Master and one or more Mirrors, operations performed on the Master will be executed and replicated to the mirrors, this implies that mirrored-queues can be slower than normal ones.
Replication is assigned through policies of the ha-mode parameter:
- exactly: It must be replicated exactly X times, 1 means that the queue will only exist on the Master.
- all: The queue will be replicated to all nodes in the cluster.
- nodes: The queue will be replicated to the nodes that appear in the output of rabbitmqctl cluster_status.
NOTE: They recommend a replication factor that meets quorum, for a 3-node cluster -> replication of 2, for a 5-node cluster -> replication of 3.
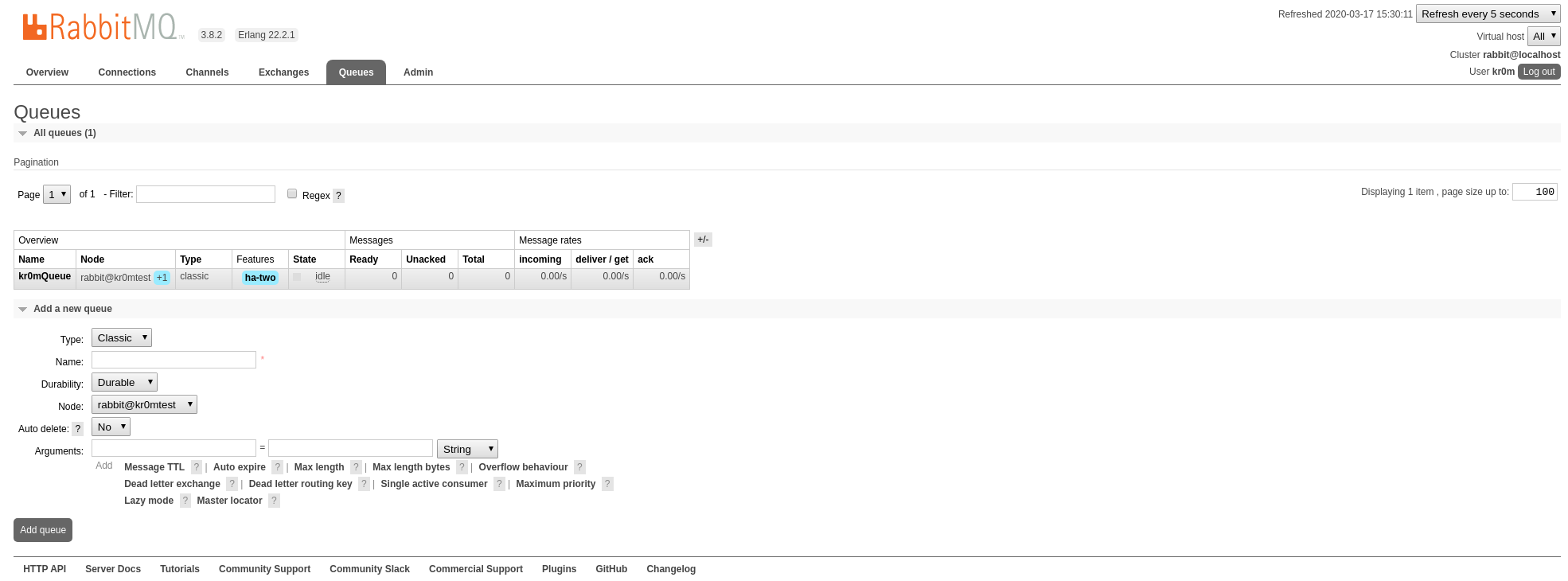
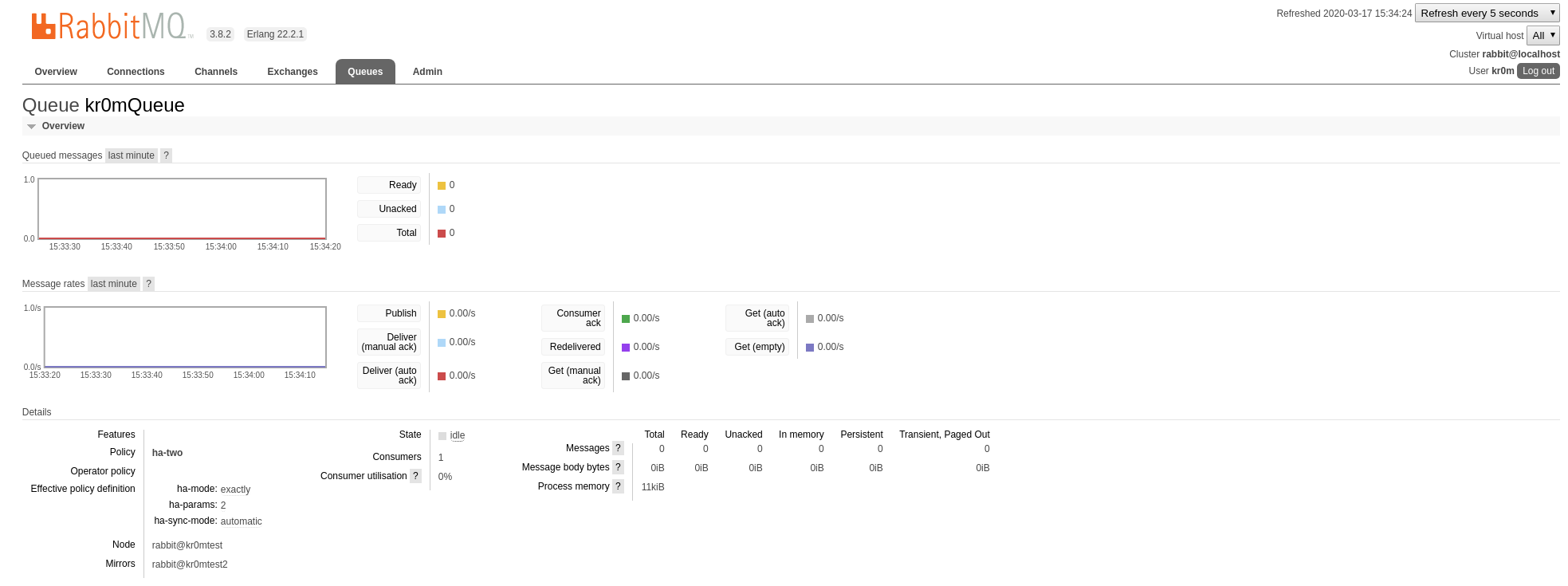
In my case, I am going to assign a replication of 2 for the kr0mQueue queue:
Setting policy "ha-two" for pattern "kr0mQueue" to "{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}" with priority "0" for vhost "/" ...
In the web interface, we can see the configuration change:
If we click on the queue, we can see where it is being replicated:
If we stop node3, we see how the mirroring migrates to another node:
The pika library provides us with an example where it connects to a cluster.
The adapted script would look like this:
import pika
import random
def on_message(channel, method_frame, header_frame, body):
print(method_frame.delivery_tag)
print(body)
print()
channel.basic_ack(delivery_tag=method_frame.delivery_tag)
## Assuming there are three hosts: host1, host2, and host3
node1 = pika.URLParameters('amqp://kr0m:s3crEt@kr0mtest/%2f')
node2 = pika.URLParameters('amqp://kr0m:s3crEt@kr0mtest2/%2f')
node3 = pika.URLParameters('amqp://kr0m:s3crEt@kr0mtest3/%2f')
all_endpoints = [node1, node2, node3]
while(True):
try:
print("Connecting...")
## Shuffle the hosts list before reconnecting.
## This can help balance connections.
random.shuffle(all_endpoints)
connection = pika.BlockingConnection(all_endpoints)
channel = connection.channel()
channel.basic_qos(prefetch_count=1)
#channel.queue_declare('recovery-example', durable = False, auto_delete = True)
channel.basic_consume('kr0mQueue', on_message)
try:
channel.start_consuming()
except KeyboardInterrupt:
channel.stop_consuming()
connection.close()
break
except pika.exceptions.ConnectionClosedByBroker:
continue
except pika.exceptions.AMQPChannelError as err:
print("Caught a channel error: {}, stopping...".format(err))
break
except pika.exceptions.AMQPConnectionError:
print("Connection was closed, retrying...")
continue
With all the nodes of the cluster up, we enqueue a message:
[x] Message sent to consumer
We see that our queue is duplicated in:
rabbit@kr0mtest2
rabbit@kr0mtest1
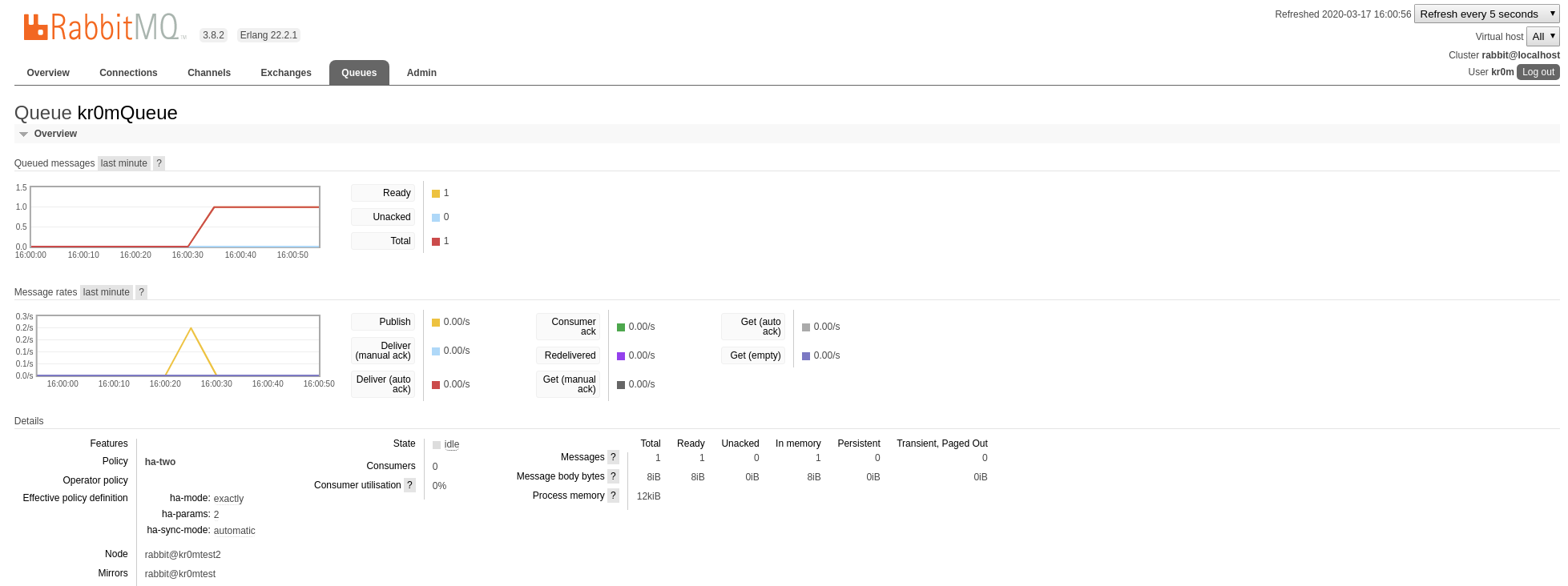
We stop node1, the queue has migrated:
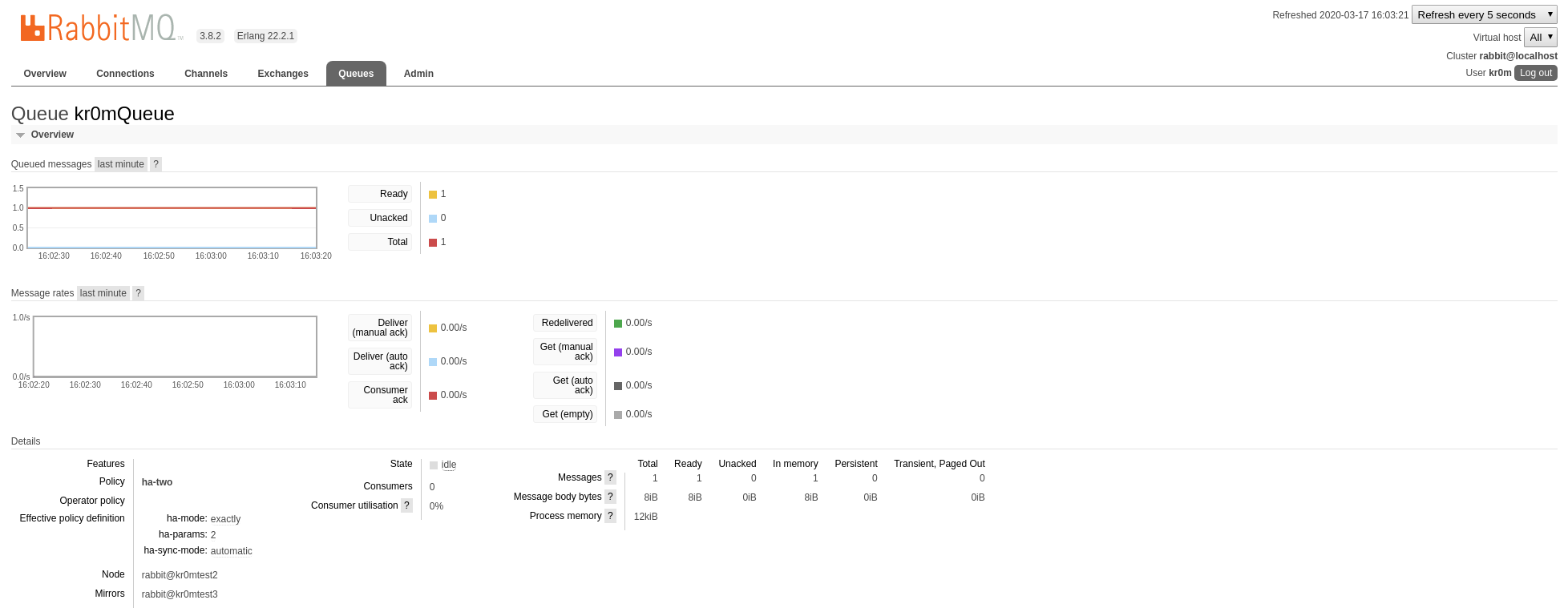
We run our consumer:
Connecting...
1
b'testBody'
NOTE: It is important to consider that the connection to the nodes is random, if the connection fails, it will only retry by choosing a new server randomly.