RabbitMQ es un software de encolado de mensajes llamado broker de mensajería o gestor de colas. Dicho de forma simple, es un software donde se pueden definir colas, las aplicaciones se pueden conectar a dichas colas y transferir/leer mensajes en ellas.
Antes de empezar debemos aclarar ciertas peculiaridades de Rabbit:
- Rabbit depende mucho de los nombres de los equipos(Erlang), todos los nodos y las herramientas de conexión que vamos a utilizar deben resolver los nombres del mismo modo(RABBITMQ_USE_LONGNAME).
- Toda la información/estados es replicada en todos los nodos a excepción de las colas(aunque si que son accesibles entre nodos)
- Hay otro tipo de cola llamado Quorum queues, pero no son durables, no se guardan en disco
- Los clusters deben de tener un número impar de nodos para evitar problemas de split-brain.
- Cuando todos los nodos están disponibles el cliente puede conectar a cada uno de ellos de forma independiente, los nodos enrutarán las operaciones al nodo que tenga la cola en cuestión de forma transparente.
- En caso de fallo de un nodo, los clientes deben ser capaces de reconectar a un nodo distinto, recuperar la topología y continuar funcionando. La mayoría de librerias cliente permiten configurar una lista de nodos.
- Puede darse el caso donde el cliente conecta a otro nodo pero la cola no existe(con la replicación de colas se solventa este problema).
- Las conexiones, canales y colas son distribuidas entre los nodos del cluster.
- Cuando se para un nodo antes de pararse elige uno de los nodos online, cuando vuelva a arrancar intentará resincronizarse desde este nodo, si no lo consigue rabbit no arrancará.
- Si cuando se está apagando un nodo no queda ningún otro nodo up, cuando se arranque no intentará sincronizar con nadie.
- El sistema de clustering está pensado para ser usado entre nodos en el mismo segmento de red, si es necesario realizar el despliegue en WAN se deben utilizar plugins como Shovel o Federation.
Compilamos e instalamos el servidor:
NOTA: He tenido que desenmascarar el servidor de rabbit porque la versión estable requiere una versión de elixir que ya no están el portage y muestra el siguiente error al compilar
(Mix) You’re trying to run :rabbitmqctl on Elixir v1.10.0 but it has declared in its mix.exs file it supports only Elixir >= 1.6.6 and < 1.9.0
Arrancamos los servidores en modo standalone para ello debemos definir las locales UTF8 en caso contrario el servicio no arrancará:
LANG="es_ES.utf8"
LC_COLLATE="C"
EOF
es_ES.utf8 UTF-8
es_ES@euro ISO-8859-15
EOF
env-update
reboot
Para que arranque hay que tener el fichero de hosts modificado para que el nombre del server apunte a la loopback:
127.0.0.1 localhost kr0mtest
#arguments for run erlang
command_args="-address 0.0.0.0"
Paramos rabbit si estaba arrancado:
Nos aseguramos de matar todos los procesos de epm(Erlang Port Mapper Daemon):
Arrancamos de nuevo, esta vez con la configuración nueva:
Consultamos cualquier posible error:
Añadimos el servicio al arranque:
NOTA: Todos los nodos del cluster deben compartir la erlang-cookie, copiamos del nodo1(por ejemplo) al resto de nodos.
Consultamos la cookie:
En el resto de nodos paramos el servicio, sustituimos la cookie y volvemos a arrancar:
vi /var/lib/rabbitmq/.erlang.cookie
/etc/init.d/rabbitmq start
Vamos a unir los nodos 2,3 al 1, para ello ejecutamos en el nodo2/3:
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@kr0mtest
rabbitmqctl start_app
El estado del cluster se puede consultar desde cualquier nodo:
Cluster status of node rabbit@kr0mtest3 ...
Basics
Cluster name: rabbit@localhost
Disk Nodes
rabbit@kr0mtest
rabbit@kr0mtest2
rabbit@kr0mtest3
Running Nodes
rabbit@kr0mtest
rabbit@kr0mtest2
rabbit@kr0mtest3
Versions
rabbit@kr0mtest: RabbitMQ 3.8.2 on Erlang 22.2.1
rabbit@kr0mtest2: RabbitMQ 3.8.2 on Erlang 22.2.1
rabbit@kr0mtest3: RabbitMQ 3.8.2 on Erlang 22.2.1
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@kr0mtest, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@kr0mtest, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@kr0mtest2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@kr0mtest2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@kr0mtest3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@kr0mtest3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: implicit_default_bindings, state: enabled
Flag: quorum_queue, state: enabled
Flag: virtual_host_metadata, state: enabled
Si necesitamos eliminar un nodo del cluster paramos la app en este y lo eliminamos desde cualquier otro nodo:
kr0mtest3 ~ # rabbitmqctl forget_cluster_node rabbit@kr0mtest4
Para poder ver de forma mas sencilla el estado del cluster/colas instalaremos el plugin de gestión, debemos hacerlo en todos los nodos:
Veremos un socket nuevo:
tcp 0 0 0.0.0.0:15672 0.0.0.0:* LISTEN 6833/beam.smp
Consultamos los usuarios:
Listing users ...
user tags
guest [administrator]
El usuario guest solo es de uso local, no se puede logear de forma remota:
This is a new features since the version 3.3.0. You can only login using guest/guest on localhost.
Creamos en uno de los nodos un usuario administrador, este sí que podrá acceder por web:
rabbitmqctl set_user_tags kr0m administrator
rabbitmqctl set_permissions -p / kr0m “.” “.” “.*”
Listing users ...
user tags
kr0m [administrator]
guest [administrator]
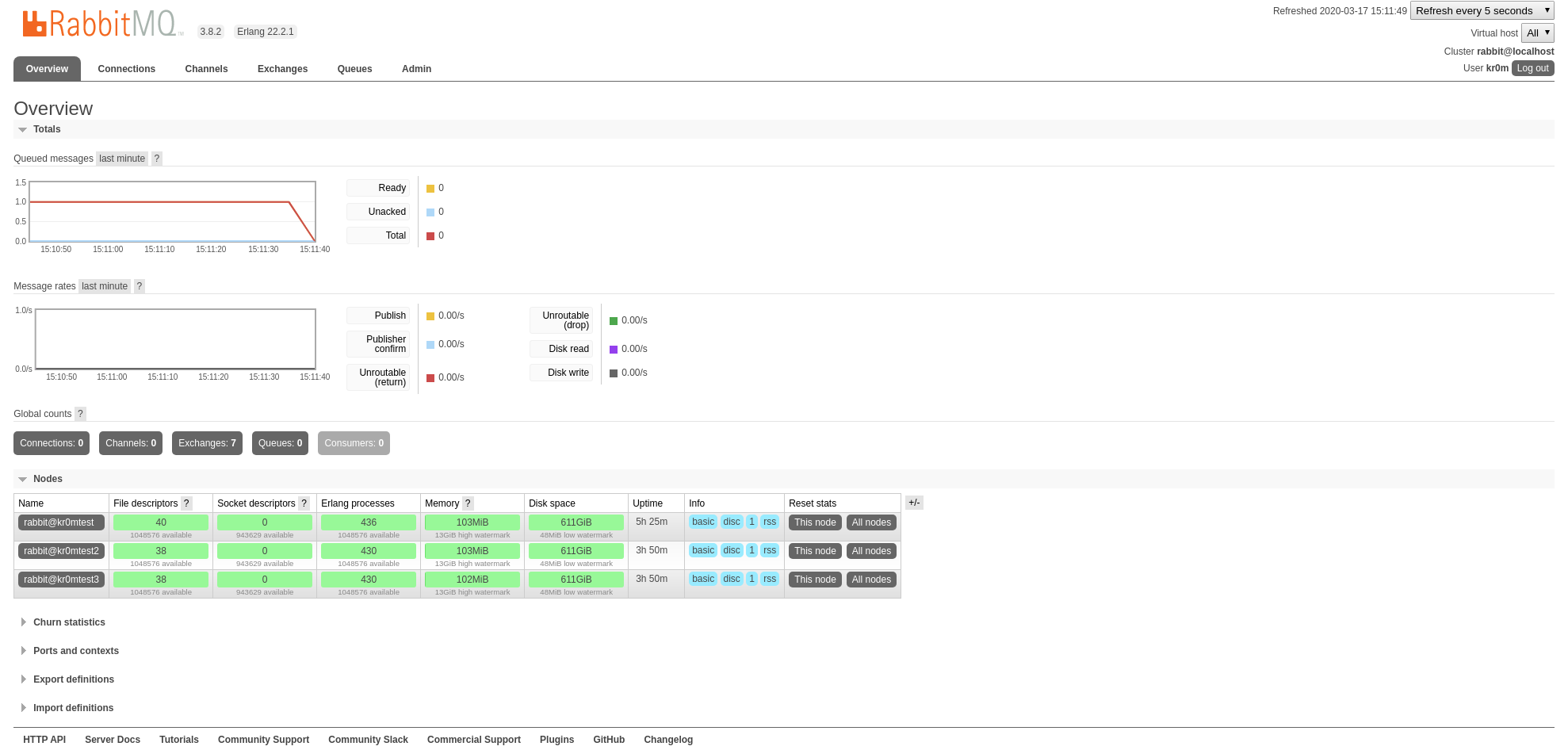
Para poder realizar nuestras pruebas desde Python tendremos que instalar la librería pika:
Vamos a crear una cola de prueba:
import pika, os, logging
logging.basicConfig()
# Parse CLODUAMQP_URL (fallback to localhost)
url = os.environ.get('CLOUDAMQP_URL', 'amqp://kr0m:s3crEt@kr0mtest/%2f')
params = pika.URLParameters(url)
params.socket_timeout = 5
connection = pika.BlockingConnection(params) # Connect to CloudAMQP
channel = connection.channel() # start a channel
channel.queue_declare(queue='kr0mQueue') # Declare a queue
# send a message
channel.basic_publish(exchange='', routing_key='kr0mQueue', body='testBody')
print ("[x] Message sent to consumer")
connection.close()
Ejecutamos el script y comprobamos que se ha creado la cola y tiene un mensaje:
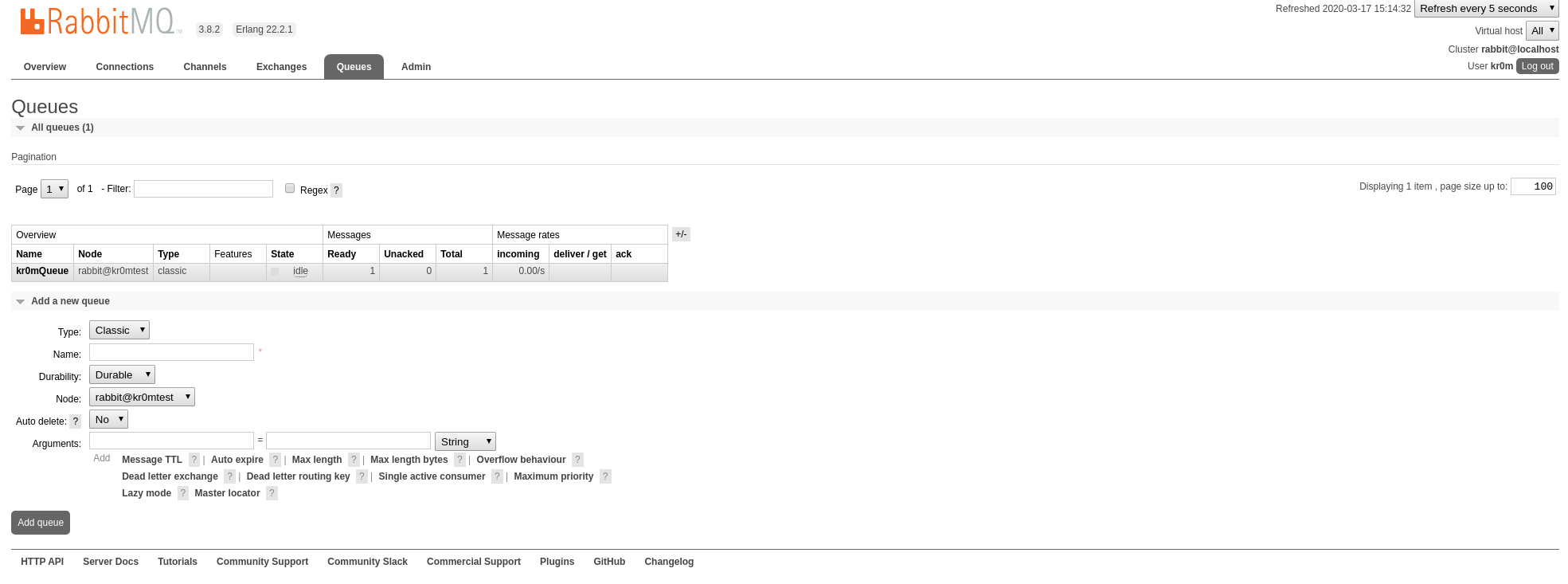
Ahora programamos un consumidor:
import pika, os
def processMessage(msg):
print(" [x] Received " + str(msg))
return;
# create a function which is called on incoming messages
def callback(ch, method, properties, body):
processMessage(body)
# Parse CLODUAMQP_URL (fallback to localhost)
url = os.environ.get('CLOUDAMQP_URL', 'amqp://kr0m:s3crEt@kr0mtest/%2f')
params = pika.URLParameters(url)
params.socket_timeout = 5
connection = pika.BlockingConnection(params) # Connect to CloudAMQP
channel = connection.channel() # start a channel
#set up subscription on the queue
channel.basic_consume('kr0mQueue', callback, auto_ack=True)
channel.start_consuming() # start consuming (blocks)
connection.close()
Podemos ver como obtiene el mensaje de la cola:
[x] Received b'testBody'
Para la sincronización de colas seguimos la guía .
Cada mirrored queue tiene un Master y uno o mas Mirrors, las operaciones realizadas en el Master se ejecutarán y se replicarán a los mirrors, esto implica que las mirrored-queues pueden ser mas lentas que las normales.
La replicación se asigna mediante políticas del parámetro ha-mode:
- exactly: Debe replicarse exactamente X veces, 1 significa que la cola solo existirá en el Master.
- all: La cola se replicará a todos los nodos del cluster.
- nodes: La cola se replicará a los nodos que aparezcan en la salida de rabbitmqctl cluster_status.
NOTA: Recomiendan un factor de replicación que cumpla quorum, para un cluster de 3 nodos -> replicación de 2, para uno de 5 nodos -> replicación de 3.
En mi caso voy a asignar una replicación de 2 para la cola kr0mQueue:
Setting policy "ha-two" for pattern "kr0mQueue" to "{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}" with priority "0" for vhost "/" ...
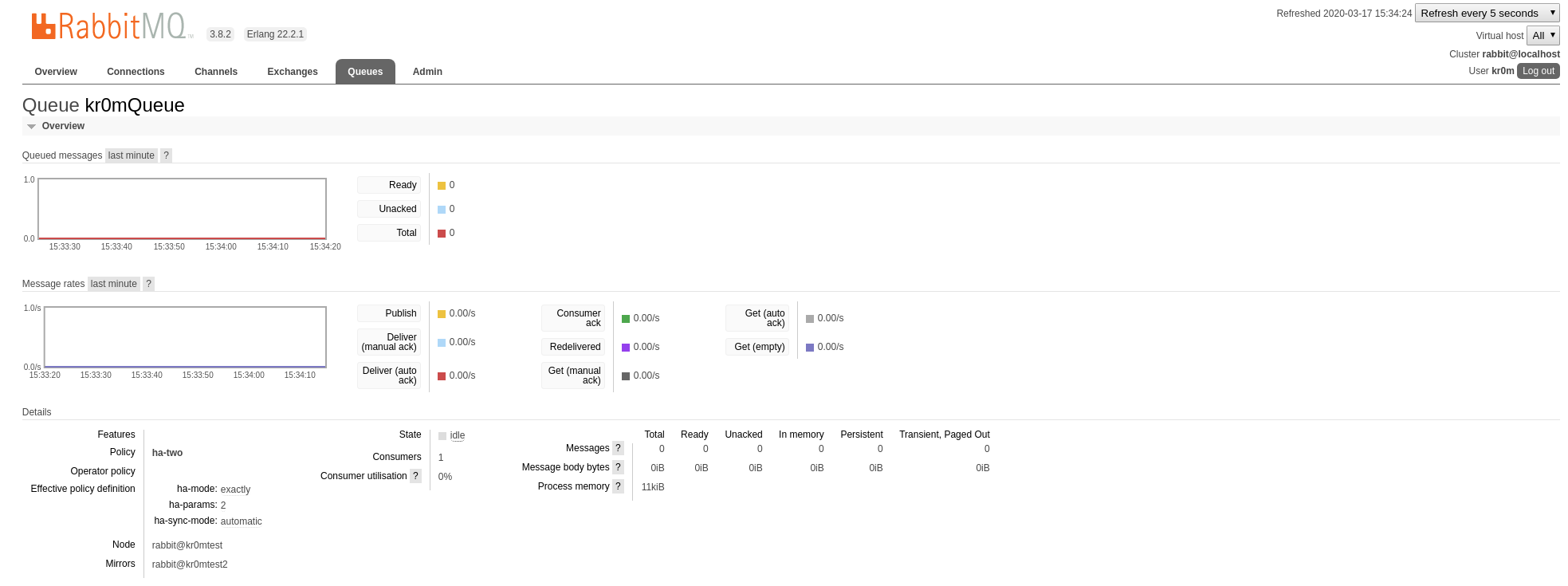
En la interfaz web podemos ver el cambio de configuración:
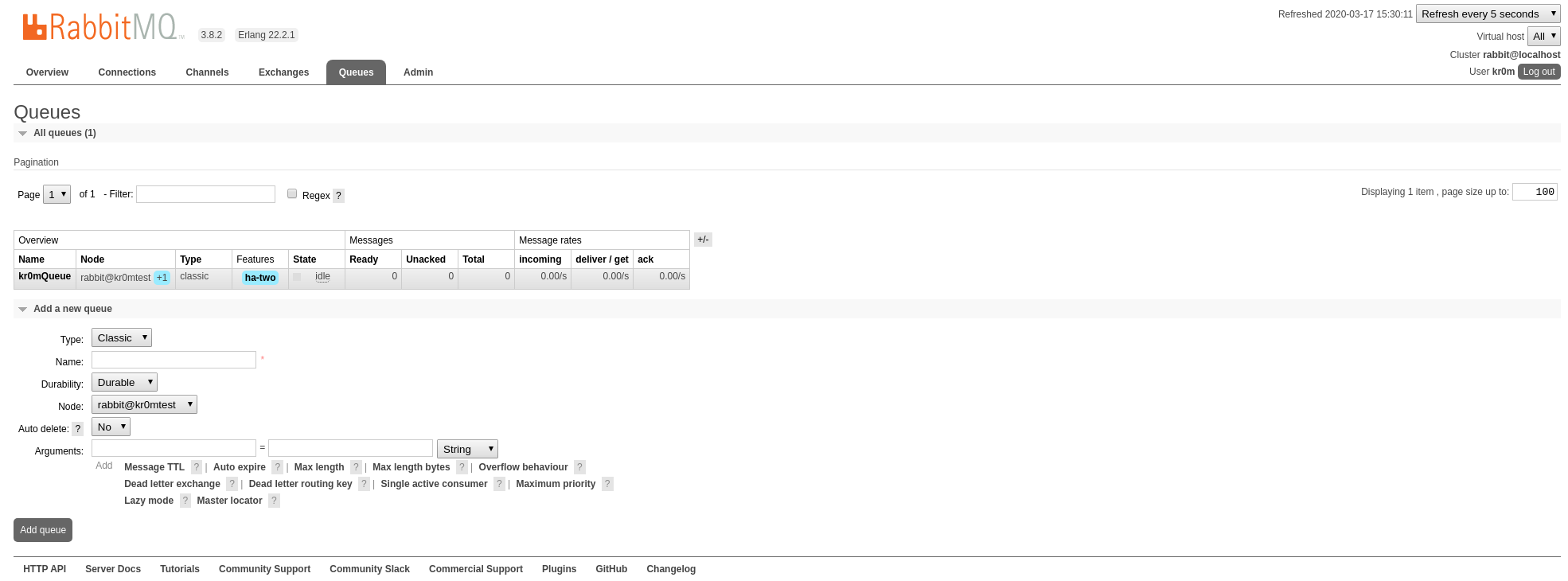
Si pinchamos en la cola podemos ver donde se está replicando:
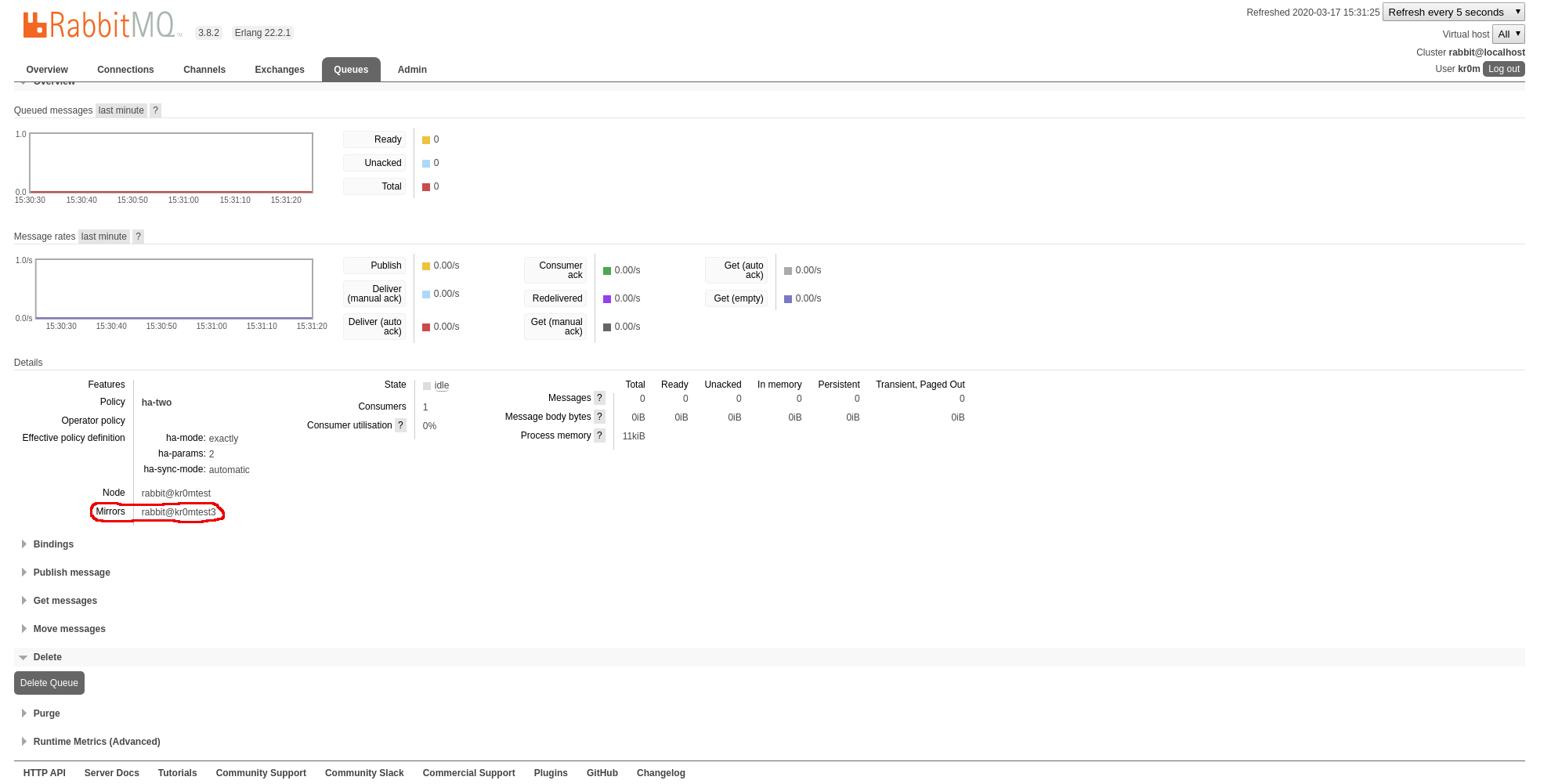
Si paramos el nodo3 vemos como se migra el mirroring a otro nodo:
La librería pika nos porporciona un ejemplo donde conecta con un cluster.
El script adapto quedaría del siguiente modo:
import pika
import random
def on_message(channel, method_frame, header_frame, body):
print(method_frame.delivery_tag)
print(body)
print()
channel.basic_ack(delivery_tag=method_frame.delivery_tag)
## Assuming there are three hosts: host1, host2, and host3
node1 = pika.URLParameters('amqp://kr0m:s3crEt@kr0mtest/%2f')
node2 = pika.URLParameters('amqp://kr0m:s3crEt@kr0mtest2/%2f')
node3 = pika.URLParameters('amqp://kr0m:s3crEt@kr0mtest3/%2f')
all_endpoints = [node1, node2, node3]
while(True):
try:
print("Connecting...")
## Shuffle the hosts list before reconnecting.
## This can help balance connections.
random.shuffle(all_endpoints)
connection = pika.BlockingConnection(all_endpoints)
channel = connection.channel()
channel.basic_qos(prefetch_count=1)
#channel.queue_declare('recovery-example', durable = False, auto_delete = True)
channel.basic_consume('kr0mQueue', on_message)
try:
channel.start_consuming()
except KeyboardInterrupt:
channel.stop_consuming()
connection.close()
break
except pika.exceptions.ConnectionClosedByBroker:
continue
except pika.exceptions.AMQPChannelError as err:
print("Caught a channel error: {}, stopping...".format(err))
break
except pika.exceptions.AMQPConnectionError:
print("Connection was closed, retrying...")
continue
Con todos los nodos del cluster up, encolamos un mensaje:
[x] Message sent to consumer
Vemos que nuestra cola está duplicada en:
rabbit@kr0mtest2
rabbit@kr0mtest1
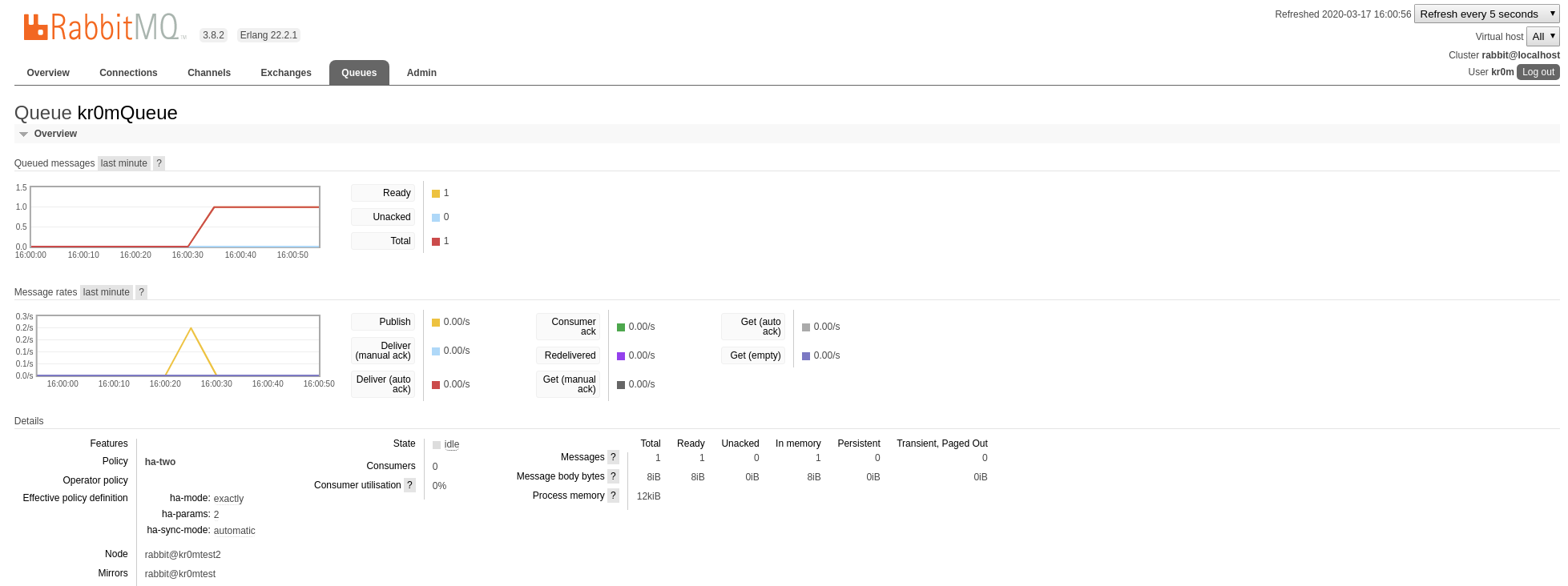
Paramos el nodo1, la cola ha migrado:
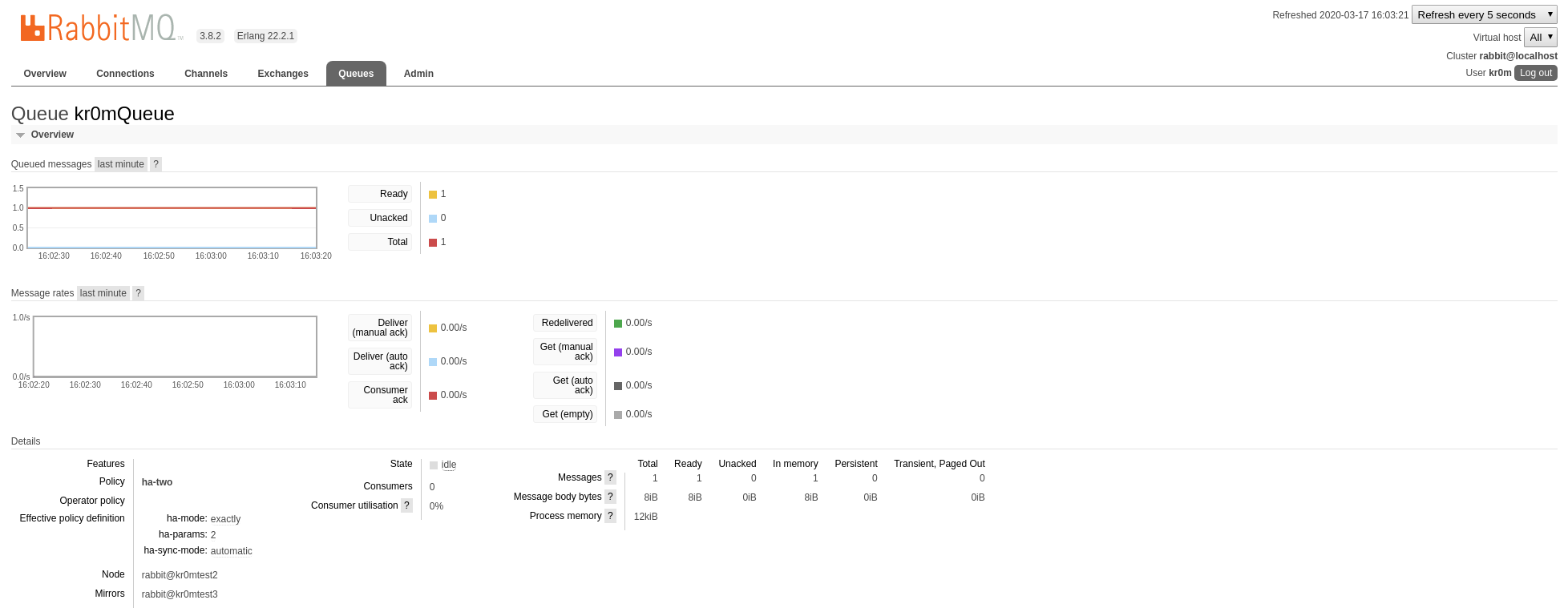
Ejecutamos nuestro consumidor:
Connecting...
1
b'testBody'
NOTA: Hay que tener en cuenta que la conexión a los nodos es random, si la conexión falla tan solo se reintenta eligiendo un servidor nuevo de forma aleatoria.